How to Efficiently Create Patient Cohorts With Sigma Computing
- Jan 18, 2023
- 6 min read
Data sharing and storage in the medical industry is a complex subject. During a single office visit, an organization may request a multitude of patient data including (but not limited to) medical history, prescriptions, allergies, test results, referring physician, and insurance policy details.
This is an immense amount of data – with many interdependencies – for one patient alone, then multiply it by the number of patients seen that day and then add varying providers and also different clinic locations, and soon it’s easy to see how an organization becomes inundated with data.
Cloud databases like the Snowflake Data Cloud have taken this problem head-on by simplifying the process of loading and storing large amounts of data, however many organizations are still left hunting for an easy solution for sharing data in meaningful ways. One example of how an organization may wish to share data intentionally is to aid in research, e.g. a search for a specific cohort of patients diagnosed with code ABC who have received drug XYZ.
Traditional business intelligence tools prefer large flat tables, which in a scenario of patients, diagnoses, and drugs administered, could easily turn into hundreds of millions ( if not billions) of rows of data leading to slow load times.
Sigma Computing has solved this problem by capitalizing on the speed and performance benefits of Snowflake, making it easy to form links between tables.
In this blog, we’ll cover how to go beyond Sigma’s built-in filtering functionality to keep data performant and separate, but still interconnected for filters.
At a Glance, How Does This Work?
This solution uses a combination of built-in functionality and the use of a “pit stop table” to get around the built-in limitations.
The built-in filters (#1) decide what rows show up in the front and back end tables. The back-end tables (#2) decide what shows up in the Patient Data, which in turn decides what shows up in the front-end diagnosis and drug name tables (#3).

Now that you get the general flow of this process, let’s go step-by-step into a specific scenario.
How to Create Patient Cohorts in Sigma
We have three different datasets in this scenario:
A Patient list
Diagnosis codes
A list of drugs administered to each patient

Step 1: Add Filters for Diagnosis Codes and Drug Names
Click on the downward-facing arrow next to the Diagnosis Code column name and select filter
Convert the filter to a page control
Click the three dots next to the filter name and select convert to page control
Repeat these steps for the Drug Names column

Step 2: Add a Lookup Column to Patient Data Based on the Diagnosis Code and Drug Name Tables
Next, link the patient table to the other two tables to see if a patient is filtered out of the diagnosis and drug table, resulting in an exclusion from the desired patient list.

Add a new column via lookup to the patient table
Source element is the Diagnosis Codes table
Add the Patient ID column
Set the Aggregate to none
Map the two elements using Patient ID in both tables
Rename column to “In Other Tables?”
This column’s function says that if the Patient ID from the Patient Data table is in the Diagnosis Code, show the Patient ID. Since we already know the patient ID, we can change this to a boolean (True/False) asking if the Patient ID is in the Diagnosis Code Table.
If the Patient ID is filtered out of the Diagnosis Code table, the lookup will return Null so we’ll use the IsNotNull function to confirm the patient ID is in both tables.
Formula:
IsNotNull(Lookup([Diagnosis Codes/Patient ID], [Patient ID], [Diagnosis Codes/Patient ID]))
Step 3: Check if the Patient ID is Also in the Drug Name Table
Since we want to be able to filter on either the Diagnosis Code table or the Drug Name table, we need to adjust the lookup to see if the Patient ID is also in the Drug Name table.
Add a second lookup function referencing the Drug Name Table
Formula:
IsNotNull(Lookup([Diagnosis Codes/Patient ID], [Patient ID], [Diagnosis Codes/Patient ID])) and IsNotNull(Lookup([Drug Names/Patient ID], [Patient ID], [Drug Names/Patient ID]))

Step 4: Filter out Patients that are not in Other Tables
Add a filter to keep only the True values of “In Other Tables?”

Now, if we apply a Diagnosis Code filter, we can see that both the Patient Data and Diagnosis Code tables update. However, the Drug Name list still contains all of the original data.

Lookups can only be performed in one direction, meaning a table that is used as a target (Diagnosis Codes and Drug Names) can not also be used as a source for a lookup in the first source table (Patient Data).

To solve for Lookups only being in one direction, we’re going to create placeholder duplicate tables that can be used in lookups.
Step 5: Rename the Diagnosis Codes and Drug Name Tables to Back End | Diagnosis Codes and Back End | Drug Name
Edit the title of these table elements to make them easier to identify.

Step 6: Re-add the Diagnosis Codes and Drug Name Tables
You can not duplicate the current elements because Sigma will view those as child elements
(I’ve renamed these to Front End tables to help reduce confusion)
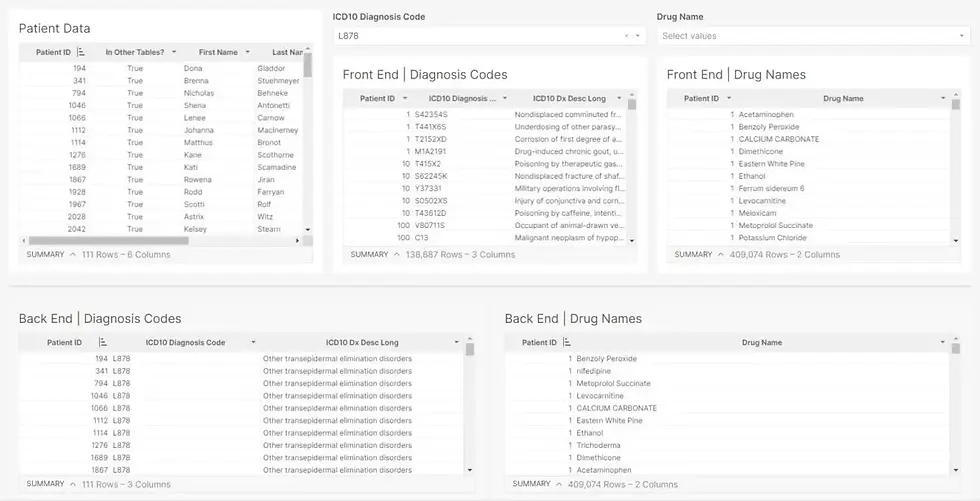
Step 7: Add the Front-end Tables as the Source and Targets for the Diagnosis Code and Drug Name Filters
Click on the filter
Change the value source to the front-end table
Click targets
Add target
Select the front-end version of the table

Step 8: Add a Lookup in the Front-End Tables to Look for the Patient ID in the Patient Data Table
Now we’re going to add a lookup that determines if the Patient ID from the front end tables are in the Patient ID table because the Code and Drug Name filters are filtering out the Patient, we need the Front End tables to match.
In the Front End Diagnosis Codes Table add a column via Lookup and wrap it in IsNotNull or add a new column and type in the function below.
IsNotNull(Lookup([Patient Data/Patient ID], [Patient ID], [Patient Data/Patient ID]))
Rename column to “In the Patient Data Table?”
In the Front End Drug Names Table add a column via Lookup and wrap it in IsNotNull or add a new column and type in the function below.
IsNotNull(Lookup([Patient Data/Patient ID], [Patient ID], [Patient Data/Patient ID]))
Rename column to “In the Patient Data Table?”

Step 9: Filter out Patients that are not in Other Tables
Add a filter to keep only the True values of “In the Patient Data Table?” for both the front-end tables

Now we can see the front-end Drug Name table has been reduced in rows to show what drugs the patients diagnosed with L878 have received.

And if we apply a drug name filter, we can see the Patient Data and Front End Diagnosis Code tables have been affected even though the back end Diagnosis Code table hasn’t been.

Step 10: Hide Unnecessary Elements
To help provide a better end-user experience, hide the lookup columns by selecting “In other Tables?” then click on the downward-facing arrow next to the column name and select hide.
Move the back-end tables to a separate tab and hide the tab. To move the elements, click on the three dots in the top right corner of each backend table and select move to and then a new page. Then right-click on that page name and select hide.

Conclusion
In conclusion, Sigma offers a powerful and efficient solution for creating patient cohorts in the medical industry through the use of its built-in filters and lookup functions. By linking the different types of tables, you will be able to keep immensely large datasets separate to maximize performance with Snowflake, but still have them interconnected for meaningful patient analysis.
FAQs
How Can I Improve Performance With This Setup?
One way to improve performance would be to set your filters to be on diagnosis or drug codes and use a display filter for a more user-friendly experience. Snowflake will perform better with shorter code as a cluster key. Another option is to utilize Snowflake’s auto-resizing feature to increase the warehouse size available when users are interacting with the workbook.

What If I Want To See All The Results In One Table?
To see all the results in one table, you can create a join using the Patient Data Table and the Front End Tables. These workbook elements have been filtered down so a join should perform well.
What If I Have More Than 3 Tables?
As long as there is one unique key in each table (for example, Patient ID), you can add as many tables as you’d like. To add additional tables, follow the steps listed above for each type of table (Codes and Drugs) and add an additional “and” statement to the “In other tables?” in your base table.

This content was originally posted on phData’s website. Click here to read the original post


